-
TensorFlow 기초 12 - 다중선형회귀모델 작성 후 텐서보드(모델의 구조 및 학습과정/결과를 시각화) -TensorFlow 2022. 11. 30. 16:27
<방법1>
# 다중선형회귀모델 작성 후 텐서보드(모델의 구조 및 학습과정/결과를 시각화) from keras.models import Sequential from keras.layers import Dense import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf # 5명의 학생이 3회 시험 실시 후 다음번 시험 점수 예측 x_data = np.array([[70, 85, 80], [71, 89, 78], [50, 80, 60], [66, 20, 60],[50, 30, 10]]) y_data = np.array([73, 82, 72, 57, 34]) # 모델 설계 print('Sequential api') model = Sequential() # model.add(Dense(1, input_dim=3, activation='linear')) # layer 1개 model.add(Dense(6, input_dim=3, activation='linear', name='a')) # layer 1개 model.add(Dense(3, activation='linear', name='b')) # name은 각 층의 이름을 부여하고 나중에 에러가 났을 때 찾기 쉬워진다. model.add(Dense(1, activation='linear', name='c')) print(model.summary()) # 일반적으로 층의 뉴런(노드) 수를 늘리기보다 층수를 늘리는 것이 이득이 많다. opti = tf.keras.optimizers.Adam(learning_rate=0.01) model.compile(optimizer=opti, loss='mse', metrics=['mse']) history = model.fit(x_data, y_data, batch_size=1, epochs=30, verbose=0) # 시각화 # plt.plot(history.history['loss']) # plt.xlabel('epochs') # plt.ylabel('loss') # plt.show() loss_metrics = model.evaluate(x_data, y_data, batch_size=1, verbose=0) print('loss_metrics :', loss_metrics) from sklearn.metrics import r2_score print('설명력 :', r2_score(y_data, model.predict(x_data, batch_size=1, verbose=0))) # 0.8688 <console> Sequential api Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= a (Dense) (None, 6) 24 b (Dense) (None, 3) 21 c (Dense) (None, 1) 4 ================================================================= Total params: 49 Trainable params: 49 Non-trainable params: 0 _________________________________________________________________ None loss_metrics : [37.1617317199707, 37.1617317199707] 설명력 : 0.8688903146972039모델 설계 시 name을 부여하면 각 층의 이름을 부여할 수 있다. 텐서보드를 활용하여 오류를 개선할 때 효율적이다.
일반적으로 층의 뉴런(노드) 수를 늘리기보다 층수를 늘리는 것이 이득이 많다.(참고일 뿐 절대적은 아니다. 참고용)
텐서보드(TensorBoard)
알고리즘을 시각화, 복잡한 모델의 수행 도중 발생하는 논리적 오류 등을 개선하기 도구이다.
TensorFlow의 시각화 툴킷이다.
<방법2>
print('functional api') from keras.layers import Input from keras.models import Model inputs = Input(shape=(3,)) output1 = Dense(6, activation='linear', name='a')(inputs) output2 = Dense(3, activation='linear', name='b')(output1) output3 = Dense(1, activation='linear', name='c')(output2) model2 = Model(inputs, output3) opti = tf.keras.optimizers.Adam(learning_rate=0.01) model2.compile(optimizer=opti, loss='mse', metrics=['mse']) # 텐서보드(TensorBoard) : 알고리즘을 시각화, 복잡한 모델의 수행 도중 발생하는 논리적 오류 등을 개선하기 도구, TensorFlow의 시각화 툴킷 from keras.callbacks import TensorBoard tb = TensorBoard(log_dir='./my', histogram_freq=1, write_graph=True, write_images=False, update_freq='epoch', profile_batch=2, embeddings_freq=1) history = model2.fit(x_data, y_data, batch_size=1, epochs=30, verbose=0, callbacks=[tb]) # TensorBoard # 해당 .py 파일 있는 디렉토리에서 실행 # tensorboard --logdir my/ loss_metrics = model2.evaluate(x_data, y_data, batch_size=1, verbose=0) print('loss_metrics :', loss_metrics) print('설명력 :', r2_score(y_data, model2.predict(x_data, batch_size=1, verbose=0))) # 0.89948 <console> functional api loss_metrics : [28.490924835205078, 28.490924835205078] 설명력 : 0.8994816443892611my라는 팩키지가 생성되며 그 안에 여러 파일이 생긴다.
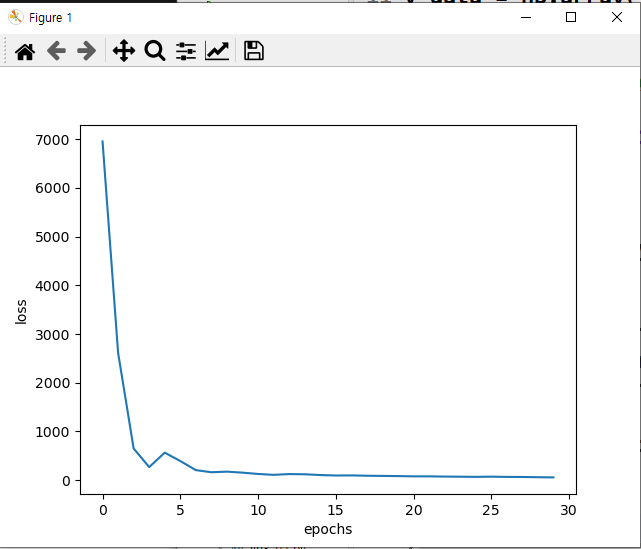
학습률과 loss의 시각화 
아나콘다 프롬프트에 들어가서 프로젝트 경로를 복사 후 들어간 뒤, tensorboard --logdir my/(생성명)을 입력한다. 서버가 활성화된다.
TensorBoard
해당 .py 파일 있는 디렉토리에서 실행
활성화된 서버에 들어가면 그래프, 스칼라 등을 확인할 수 있다. 다운로드도 가능하다.
'TensorFlow' 카테고리의 다른 글
다중선현회귀모델 예제 - 주식 데이터로 예측 모형 작성. 전날 데이터로 다음날 종가 예측(train/test split, validation_split) (0) 2022.12.01 TensorFlow 기초 13 - 다중선형회귀모델(scaling) - 정규화, 표준화 validation_split (0) 2022.11.30 단순선형회귀 방법 1, 방법 2 예제(Sequential api, Function api) (0) 2022.11.30 TensorFlow 기초 11 - 단순선형회귀모델 작성 : 방법 3가지(다중 입출력 모델) (0) 2022.11.30 TensorFlow 기초 10 - 선형회귀분석 예제(예측, 결정계수) (0) 2022.11.30