-
다중선현회귀모델 예제 - 주식 데이터로 예측 모형 작성. 전날 데이터로 다음날 종가 예측(train/test split, validation_split)TensorFlow 2022. 12. 1. 11:12
과적합 방지를 위해 train / test split 을 하기 전과 하고 난 후, 그리고 train / test validation 후의 모델을 나눠보았다.
# 주식 데이터로 예측 모형 작성. 전날 데이터로 다음날 종가 예측 import numpy as np from keras.models import Sequential from keras.layers import Dense import tensorflow as tf import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler xy =np.loadtxt('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/stockdaily.csv', delimiter=',', skiprows=1) print(xy[:2], xy.shape) # (732, 5) x_data = xy[:, 0:-1] scaler = MinMaxScaler(feature_range=(0, 1)) # 정규화 처리 x_data = scaler.fit_transform(x_data) # feature만 정규화 print(x_data[:2]) y_data = xy[:, [-1]] print(y_data[:2]) # 이전일 Open High Low Volume과 다음날 Close를 한 행으로 만들기 print(x_data[0], y_data[0]) print(x_data[1], y_data[1]) print() x_data = np.delete(x_data, -1, axis=0) # 마지막 x_data 행 삭제 y_data = np.delete(y_data, 0) # 첫번째 y_data 행 삭제 print(x_data[0], y_data[0]) print('-----') model = Sequential() model.add(Dense(units=1, input_dim=4, activation='linear')) model.compile(optimizer='sgd', loss='mse', metrics=['mse']) model.fit(x_data, y_data, epochs=200, verbose=0) print('train/test 없이 평가 :', model.evaluate(x_data, y_data, verbose=0)) print(x_data[10]) test = x_data[10].reshape(-1, 4) print('실제값 :', y_data[10]) print('예측값 :', model.predict(test)) print() pred = model.predict(x_data) from sklearn.metrics import r2_score print('train/test 없이 평가 :', r2_score(y_data, pred)) # 0.9938 과적합 의심 # train/test 전 모델로 시각화 plt.plot(y_data, 'b') plt.plot(pred, 'r--') plt.show() # 순서가 중요하기 때문에 셔플이 되면 안 된다. print('\n과적합 방지를 목적으로 학습/검정 데이터로 분리') print(len(x_data)) train_size = int(len(x_data) * 0.7) test_size = len(x_data) - train_size print(train_size, ' ', test_size) x_train, x_test = x_data[0:train_size], x_data[train_size:len(x_data)] y_train, y_test = y_data[0:train_size], y_data[train_size:len(x_data)] print(x_train[:2], x_train.shape) print(x_test[:2], x_test.shape) from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3, shuffle=False) print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (511, 4) (220, 4) (511,) (220,) print('--------') model2 = Sequential() model2.add(Dense(units=1, input_dim=4, activation='linear')) model2.compile(optimizer='sgd', loss='mse', metrics=['mse']) model2.fit(x_train, y_train, epochs=200, verbose=0) print('train/test split 후 평가 :', model2.evaluate(x_test, y_test, verbose=0)) print(x_test[10]) test = x_test[10].reshape(-1, 4) print('실제값 :', y_test[10]) print('예측값 :', model2.predict(test)) print() pred2 = model2.predict(x_test) print('train/test split 후 평가 :', r2_score(y_test, pred2)) # 0.947 # train/test split 후 모델로 시각화 plt.plot(y_test, 'b') plt.plot(pred2, 'r--') plt.show() print('--------') model3 = Sequential() model3.add(Dense(units=1, input_dim=4, activation='linear')) model3.compile(optimizer='sgd', loss='mse', metrics=['mse']) model3.fit(x_train, y_train, epochs=200, verbose=0, validation_split=0.15) print('train/test validation 후 평가 :', model2.evaluate(x_test, y_test, verbose=0)) pred3 = model3.predict(x_test) print('train/test validation 후 평가 :', r2_score(y_test, pred3)) # 0.947 # train/test validation 후 모델로 시각화 plt.plot(y_test, 'b') plt.plot(pred3, 'r--') plt.show() # 머신러닝의 이슈 : 모델의 최적화와 일반화 사이의 줄다리기다~ <console> [[8.28659973e+02 8.33450012e+02 8.28349976e+02 1.24770000e+06 8.31659973e+02] [8.23020020e+02 8.28070007e+02 8.21655029e+02 1.59780000e+06 8.28070007e+02]] (732, 5) [[0.97333581 0.97543152 1. 0.11112306] [0.95690035 0.95988111 0.9803545 0.14250246]] [[831.659973] [828.070007]] [0.97333581 0.97543152 1. 0.11112306] [831.659973] [0.95690035 0.95988111 0.9803545 0.14250246] [828.070007] [0.97333581 0.97543152 1. 0.11112306] 828.070007 ----- 2022-12-01 11:04:23.670913: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. train/test 없이 평가 : [62.614986419677734, 62.614986419677734] [0.88894325 0.88357424 0.90287217 0.10453527] 실제값 : 801.48999 1/1 [==============================] - ETA: 0s 1/1 [==============================] - 0s 31ms/step 예측값 : [[796.23254]] 1/23 [>.............................] - ETA: 0s 23/23 [==============================] - 0s 318us/step train/test 없이 평가 : 0.993861859034064 과적합 방지를 목적으로 학습/검정 데이터로 분리 731 511 220 [[0.97333581 0.97543152 1. 0.11112306] [0.95690035 0.95988111 0.9803545 0.14250246]] (511, 4) [[0.10097438 0.12060001 0.11549761 0.1561262 ] [0.097186 0.10412462 0.1128567 0.11291566]] (220, 4) (511, 4) (220, 4) (511,) (220,) -------- train/test split 후 평가 : [34.382816314697266, 34.382816314697266] [0.10292681 0.10036705 0.08988032 0.16994712] 실제값 : 535.212448 1/1 [==============================] - ETA: 0s 1/1 [==============================] - 0s 18ms/step 예측값 : [[524.8133]] 1/7 [===>..........................] - ETA: 0s 7/7 [==============================] - 0s 333us/step train/test split 후 평가 : 0.9481664118667508 -------- train/test validation 후 평가 : [34.382816314697266, 34.382816314697266] 1/7 [===>..........................] - ETA: 0s 7/7 [==============================] - 0s 333us/step train/test split 후 평가 : 0.8351870732674049
train/test 전 모델로 시각화 과적합 의심

train/test split 후 모델로 시각화 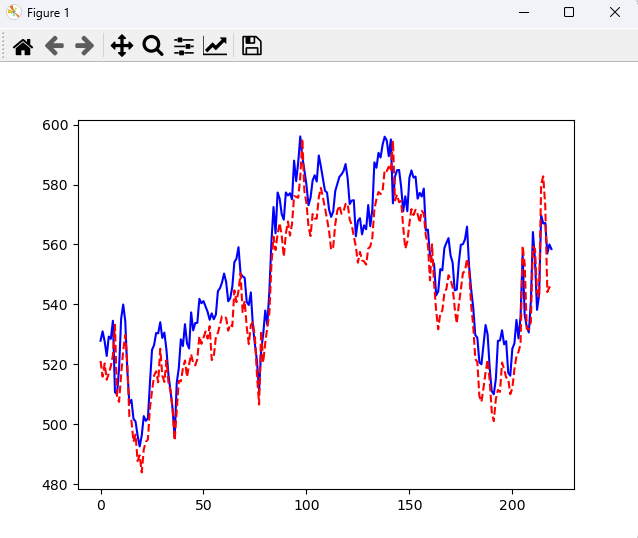
train/test validation 후 모델로 시각화 'TensorFlow' 카테고리의 다른 글
TensorFlow 기초 14 - 선형회귀용 다층 분류모델 - Sequential, Functional api(표준화 및 validation_data) (1) 2022.12.01 다중선형회귀 예제 - 자전거 공유 시스템 분석 (0) 2022.12.01 TensorFlow 기초 13 - 다중선형회귀모델(scaling) - 정규화, 표준화 validation_split (0) 2022.11.30 TensorFlow 기초 12 - 다중선형회귀모델 작성 후 텐서보드(모델의 구조 및 학습과정/결과를 시각화) - (0) 2022.11.30 단순선형회귀 방법 1, 방법 2 예제(Sequential api, Function api) (0) 2022.11.30