-
Python 데이터분석 기초 37 - 일원분산분석으로 평균차이 검정(웹에서 데이터 가져오기)Python 데이터 분석 2022. 11. 9. 12:41
# 일원분산분석으로 평균차이 검정 : 한 개의 요인에 따른 여러 개의 집단으로 데이터가 구성 # 강남구에 있는 GS 편의점 3개 지역 알바생의 급여에 대한 평균차이 검정을 실시 # 귀무 : 강남구에 있는 GS 편의점 알바생의 급여에 대한 평균은 차이가 없다. # 대립 : 강남구에 있는 GS 편의점 알바생의 급여에 대한 평균은 차이가 있다. import pandas as pd import scipy.stats as stats from statsmodels.formula.api import ols import matplotlib.pyplot as plt import numpy as np import urllib.request from statsmodels.stats.anova import anova_lm url = "https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/group3.txt" # data = pd.read_csv(url, header = None) # pandas로 읽기(DataFrame으로 가져와진다.) # print(data.head(3), type(data)) # print(data.describe()) # 아웃라이어, 결측치가 있는지 확인 # data = data.values # print(data[:3], type(data)) print() data = np.genfromtxt(urllib.request.urlopen(url), delimiter = ',') # numpy로 읽기(numpy.ndarray로 가져와진다.) print(data[:3], type(data)) # 세 지역 급여 평균 확인 gr1 = data[data[:, 1] == 1, 0] # 1열에 값이 1인 것의 0열 gr2 = data[data[:, 1] == 2, 0] # 1열에 값이 2인 것의 0열 gr3 = data[data[:, 1] == 3, 0] # 1열에 값이 3인 것의 0열 print('gr1 : ', np.mean(gr1)) # 316.6 print('gr2 : ', np.mean(gr2)) # 256.4 print('gr3 : ', np.mean(gr3)) # 278.0 차이? print() # 정규성 확인 print(stats.shapiro(gr1).pvalue) # 0.3336 > 0.05 이므로 정규성 만족 print(stats.shapiro(gr2).pvalue) # 0.6561 > 0.05 이므로 정규성 만족 print(stats.shapiro(gr3).pvalue) # 0.8324 > 0.05 이므로 정규성 만족 # 등분산성 확인 print(stats.levene(gr1, gr2, gr3).pvalue) # 표본수가 클 때는 이걸로 간다. 0.0458 < 0.05 만족 못함. 하지만 0.05에 근접하면 그냥 가도 된다. 물론 welch_anova를 사용할 수도 있다. (등분산성 만족 못할 시) print(stats.bartlett(gr1, gr2, gr3).pvalue) # 표본수가 적을 때는 이걸로 간다. # 데이터의 퍼짐 정도 시각화 # plt.boxplot([gr1, gr2, gr3], showmeans = True) # plt.show() # 일원분산분석 방법1 : anova_lm df = pd.DataFrame(data, columns = ['pay', 'group']) print(df.head(3)) lmodel = ols('pay ~ C(group)', data = df).fit() # 범주형이 종속변수 print(anova_lm(lmodel, typ=1)) # 해석 : p-value 0.043589 < 0.05 이므로 귀무가설 기각. 대립가설 채택. # 강남구에 있는 GS 편의점 알바생의 급여에 대한 평균은 차이가 있다. print() # 일원분산분석 방법2 : f_oneway() f_sta, pvalue = stats.f_oneway(gr1, gr2, gr3) print('f통계량 : ', f_sta) # 3.7113 print('유의확률 : ', pvalue) # 0.0435 # 각 지역의 평균차이가 궁금. 사후검정 수행 # post hoc test from statsmodels.stats.multicomp import pairwise_tukeyhsd turkeyResult = pairwise_tukeyhsd(endog = df.pay, groups = df.group) print(turkeyResult) # 차이가 없으면 reject가 False가 나오고, 차이가 크면 True가 나온다. # 시각화 turkeyResult.plot_simultaneous(xlabel = 'mean', ylabel = 'group') plt.show() <console> [[243. 1.] [251. 1.] [275. 1.]] <class 'numpy.ndarray'> gr1 : 316.625 gr2 : 256.44444444444446 gr3 : 278.0 0.3336853086948395 0.6561065912246704 0.832481324672699 0.045846812634186246 0.3508032640105389 pay group 0 243.0 1.0 1 251.0 1.0 2 275.0 1.0 df sum_sq mean_sq F PR(>F) C(group) 2.0 15515.766414 7757.883207 3.711336 0.043589 Residual 19.0 39716.097222 2090.320906 NaN NaN f통계량 : 3.7113359882669763 유의확률 : 0.043589334959178244 Multiple Comparison of Means - Tukey HSD, FWER=0.05 ====================================================== group1 group2 meandiff p-adj lower upper reject ------------------------------------------------------ 1.0 2.0 -60.1806 0.0355 -116.619 -3.7421 True 1.0 3.0 -38.625 0.3215 -104.8404 27.5904 False 2.0 3.0 21.5556 0.6802 -43.2295 86.3406 False ------------------------------------------------------2가지 방법으로 일원분산분석을 진행했다.
각 지역의 평균차이가 얼마만큼 있는지도 알아보기 위해 사후검정도 수행했다.
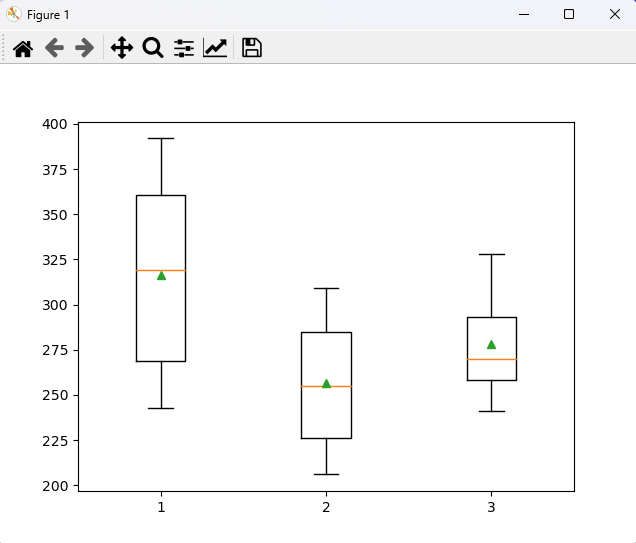
데이터의 퍼짐 정도 시각화 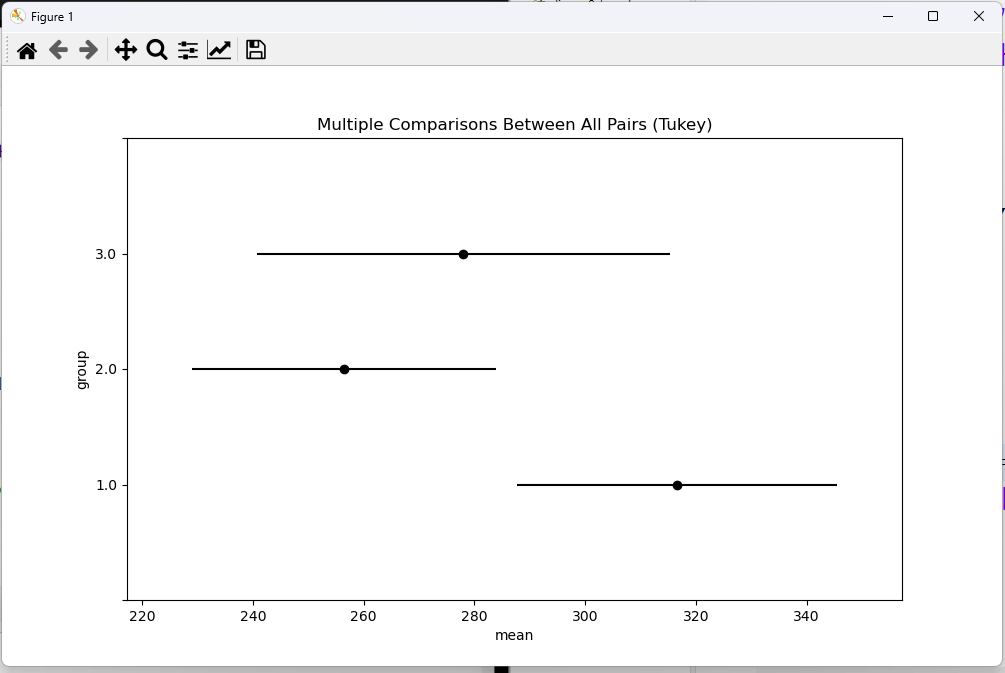
사후검정 수행 후 시각화 'Python 데이터 분석' 카테고리의 다른 글
ANOVA 예제 1, 2(정규성, 등분산성 검정, 사후 검정) 귀무 vs 대립 (1) 2022.11.09 Python 데이터분석 기초 38 - 어느 음식점 매출 자료와 날씨 자료를 활용하여 온도(추움, 보통, 더움)에 따른 매출액 평균에 차이를 검정 + 웹 (0) 2022.11.09 Python 데이터분석 기초 36 - 세 개 이상의 모집단에 대한 가설검정 – 분산분석(ANOVA), 사후검정 (0) 2022.11.09 t-test 검정 문제(2) DB 예제, 정규성 확인 (0) 2022.11.08 t-test 검정 문제(1) 정규성 확인 (0) 2022.11.08