-
NaiveBayes 분류모델 - GaussanNB 예제Python 데이터 분석 2022. 11. 24. 18:14

<작성자 코드>
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score from sklearn import metrics from sklearn.preprocessing import LabelEncoder from xgboost import plot_importance import matplotlib.pyplot as plt import xgboost as xgb df = pd.read_csv('../testdata/mushrooms.csv') print(df.head(3)) print(df.info()) le = LabelEncoder() # for 문으로 각 칼럼들을 넣어 인코딩하였다. for col in df.columns: df[col] = le.fit_transform(df[col]) print(df.head(3)) x = df.drop(columns = ['class']) y = df['class'] print(x[:3]) print(y[:3]) # 8 : 2 split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 1) print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (6499, 22) (1625, 22) (6499,) (1625,) # 주요 변수 모델링 및 시각화 model = xgb.XGBClassifier(booster = 'gbtree', max_depth = 6, n_estimators=500 ).fit(x_train, y_train) pred = model.predict(x_test) fig, ax = plt.subplots(figsize=(10, 12)) plot_importance(model, ax = ax) plt.show() features = df[['spore-print-color', 'odor', 'gill-size', 'cap-color', 'population']] labels = df['class'] # 8 : 2 split x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size = 0.2, random_state = 1) print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (6499, 22) (1625, 22) (6499,) (1625,) # model gmodel = GaussianNB() gmodel.fit(x_train, y_train) pred = gmodel.predict(x_test) print('예측값 :', pred[:10]) print('실제값 :', y_test[:10].values) acc = sum(y_test == pred) / len(pred) print('acc :', acc) print('acc :', accuracy_score(y_test, pred)) # kfold from sklearn import model_selection cross_val = model_selection.cross_val_score(gmodel, x, y, cv = 5) print('교차 검증 :', cross_val) print('교차 검증 평균값 :', cross_val.mean()) <console> class cap-shape cap-surface ... spore-print-color population habitat 0 p x s ... k s u 1 e x s ... n n g 2 e b s ... n n m [3 rows x 23 columns] <class 'pandas.core.frame.DataFrame'> RangeIndex: 8124 entries, 0 to 8123 Data columns (total 23 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 class 8124 non-null object 1 cap-shape 8124 non-null object 2 cap-surface 8124 non-null object 3 cap-color 8124 non-null object 4 bruises 8124 non-null object 5 odor 8124 non-null object 6 gill-attachment 8124 non-null object 7 gill-spacing 8124 non-null object 8 gill-size 8124 non-null object 9 gill-color 8124 non-null object 10 stalk-shape 8124 non-null object 11 stalk-root 8124 non-null object 12 stalk-surface-above-ring 8124 non-null object 13 stalk-surface-below-ring 8124 non-null object 14 stalk-color-above-ring 8124 non-null object 15 stalk-color-below-ring 8124 non-null object 16 veil-type 8124 non-null object 17 veil-color 8124 non-null object 18 ring-number 8124 non-null object 19 ring-type 8124 non-null object 20 spore-print-color 8124 non-null object 21 population 8124 non-null object 22 habitat 8124 non-null object dtypes: object(23) memory usage: 1.4+ MB None class cap-shape cap-surface ... spore-print-color population habitat 0 1 5 2 ... 2 3 5 1 0 5 2 ... 3 2 1 2 0 0 2 ... 3 2 3 [3 rows x 23 columns] cap-shape cap-surface cap-color ... spore-print-color population habitat 0 5 2 4 ... 2 3 5 1 5 2 9 ... 3 2 1 2 0 2 8 ... 3 2 3 [3 rows x 22 columns] 0 1 1 0 2 0 Name: class, dtype: int32 (6499, 22) (1625, 22) (6499,) (1625,) (6499, 5) (1625, 5) (6499,) (1625,) 예측값 : [0 1 1 1 1 1 1 0 0 0] 실제값 : [0 1 1 1 0 1 1 0 1 1] acc : 0.7341538461538462 acc : 0.7341538461538462 교차 검증 : [0.72923077 0.96123077 0.79261538 0.65230769 0.49445813] 교차 검증 평균값 : 0.7259685486926866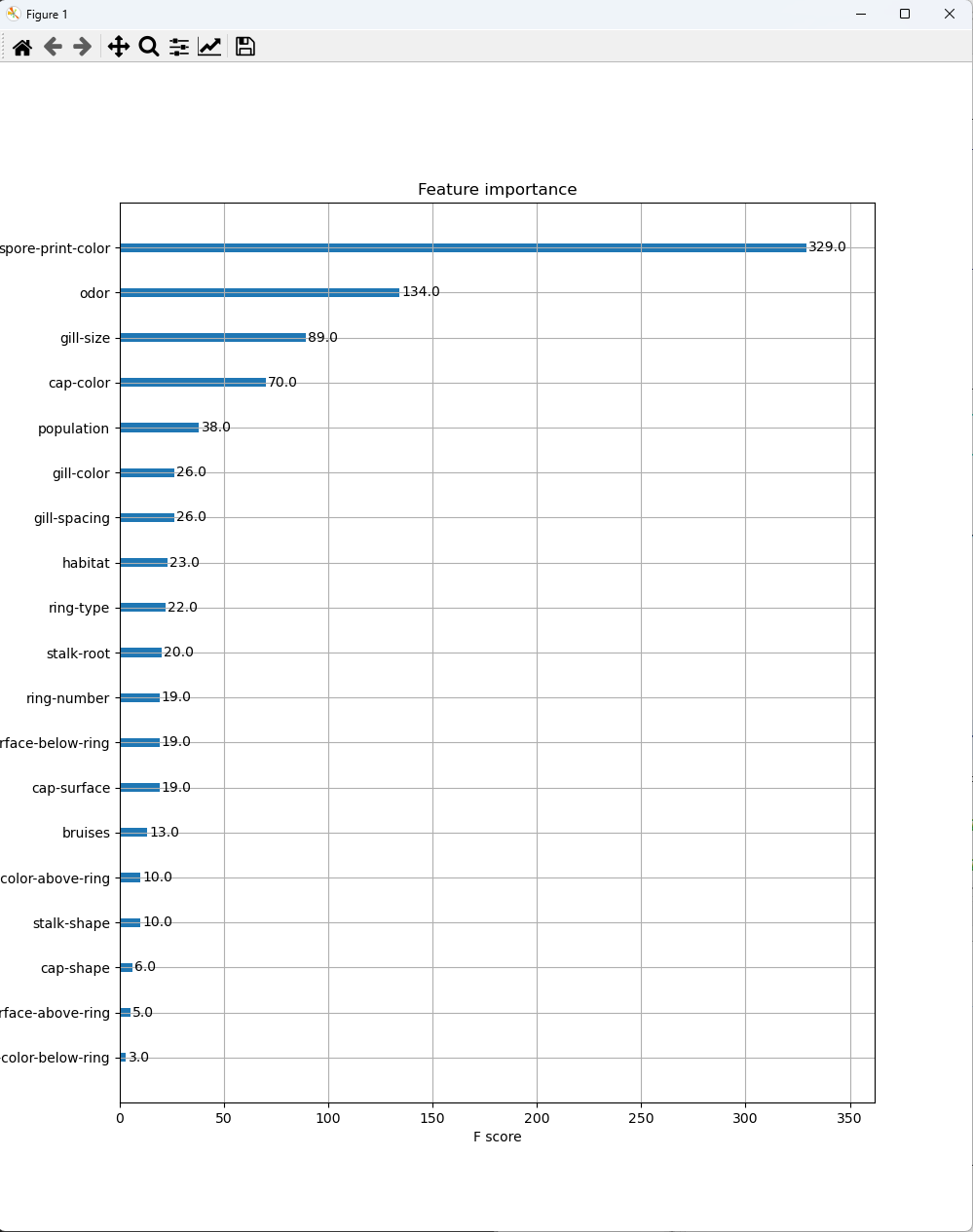
주요 변수들 시각화 'Python 데이터 분석' 카테고리의 다른 글
Python 데이터분석 기초 70 - K-NN (K-Nearest Neighber) (0) 2022.11.25 Python 데이터분석 기초 69 - K-NN (K-Nearest Neighber) (0) 2022.11.25 날씨 정보로 나이브에즈 분류기 작성 - 비 예보 (0) 2022.11.24 Python 데이터분석 기초 69 - NaiveBayes 분류모델 (0) 2022.11.24 Python 데이터분석 기초 68 - SVM으로 이미지 분류 (0) 2022.11.24