-
단순선형회귀, 다중선형회귀 예제(2), 회귀분석모형의 적절성을 위한 5가지 조건Python 데이터 분석 2022. 11. 15. 18:02
# 선형회귀분석 모델 import numpy as np import pandas as pd import matplotlib.pyplot as plt import statsmodels.api plt.rc('font', family = 'malgun gothic') import seaborn as sns import statsmodels.formula.api as smf # 여러 매체의 광고비에 따른 상품 판매량(매출액) 데이터 사용 advdf = pd.read_csv('../testdata/Advertising.csv', usecols = [1,2,3,4]) # 0번째 열은 빼고 읽기 print(advdf.head(3), advdf.shape) # (200, 4) print(advdf.info()) # 단순선형회귀 : tv, sales print('상관계수(r) :', advdf.loc[:, ['tv', 'sales']].corr()) # 상관계수 구하기, 0.782224 양의 상관관계가 강하다. # 'tv'가 'sales'에 영향을 준다 라고 가정 # 모델 생성 # lm = smf.ols(formula = 'sales ~ tv', data = advdf) # lm = lm.fit() lm = smf.ols(formula = 'sales ~ tv', data = advdf).fit() print(lm.summary()) # p-value = 1.47e-42 < 0.05 이므로 유의한 모델이다. # 시각화 # plt.scatter(advdf.tv, advdf.sales) # plt.xlabel('tv') # plt.ylabel('sales') # y_pred = lm.predict(advdf.tv) # # print('y_pred :', y_pred.values) # # print('real y :', advdf.sales.values) # plt.plot(advdf.tv, y_pred, c = 'r') # plt.show() # 예측1 : 새로운 tv 값으로 sales를 추정 x_new = pd.DataFrame({'tv':[230.1, 44.5, 100]}) pred = lm.predict(x_new) print('예측 결과 :', pred.values) print('---------') print(advdf.corr()) # tv > radio > newspaper lm_mul = smf.ols(formula = 'sales ~ tv + radio', data = advdf).fit() print(lm_mul.summary()) # p-value = 1.58e-96 < 0.05 이므로 유의한 모델이다. # 예측2 : 새로운 tv, radio 값으로 sales를 추정 x_new2 = pd.DataFrame({'tv':[230.1, 44.5, 100], 'radio':[30.0, 40.0, 50.0]}) pred2 = lm_mul.predict(x_new2) print('예측 결과 :', pred2.values) print('----------------') # 회귀분석모형의 적절성을 위한 조건 : 아래의 조건 위배 시에는 변수 제거나 조정을 신중히 고려해야 함. # 1) 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다. # 2) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다. # 3) 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 특정한 패턴을 가지면 좋지 않다. # 4) 등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다. # 5) 다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다. # 잔차항 구하기 # print(advdf.iloc[:, 0:2]) fitted = lm_mul.predict(advdf.iloc[:, 0:2]) residual = advdf['sales'] - fitted # 잔차 : 표본 데이터의 예측값과 실제값의 차이 print('residual :', residual[:3]) print(np.mean(residual)) # 5.511147094239277e-15, 잔차의 평균 print() print('선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 특정한 패턴을 가지면 좋지 않다.') # 예측값과 잔차가 비슷하게 유지되어야 함 sns.regplot(fitted, residual, lowess = True, line_kws={'color':'red'}) plt.plot([fitted.min(),fitted.max()], [0, 0], '--') plt.show() # 선형성을 만족하지 못함. 다항회귀를 추천 print() print('정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다.') # Q-Q plot으로 확인 import scipy.stats sr = scipy.stats.zscore(residual) # 표본에 있는 각 값의 z 값을 계산 (x, y), _ = scipy.stats.probplot(sr) sns.scatterplot(x, y) plt.plot([-3, 3],[-3, 3], '--', color = 'grey') plt.show() # 정규성 만족하지 못함 : log를 취하는 듯의 작업을 통해 정규분포를 따르도록 데이터 가공 작업 필요 # 정규성은 shapiro test로 확인 가능 print('shapiro test :', scipy.stats.shapiro(residual)) # pvalue=4.190036317908152e-09 < 0.05 이므로 정규성 만족 print('독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다. 잔차가 독립적이어야 한다.(자기상관이 없어야 된다.)') # Durbin-Watson : 잔차의 독립성 만족여부 확인 가능. 2에 근사하면 자기상관이 없다. 0 <- 양의 상관 - 2(독립성) - 음의 상관 > 4 # summary()로 확인한 결과 2.081 이므로 잔차의 독립성은 만족 print('등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다.') sns.regplot(fitted, np.sqrt(np.abs(sr)), lowess = True, line_kws = {'color':'red'}) plt.show() # 일정한 패턴의 곡선을 그리므로 등분산성을 만족하지 못함 # 이상값 확인, 비선형인지 확인, 정규성을 확인 # 만약에 정규성은 만족하나 등분산성을 만족하지 못하는 경우에는 가중회귀분석을 추천한다. print('다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다.') # 독립성과 밀접한 관계가 있다. # VIF(분산팽창계수)를 사용해서 확인 # VIF가 10이 넘으면 다중공선성이 있다고 판단하며 5가 넘으면 주의할 필요가 있다. from statsmodels.stats.outliers_influence import variance_inflation_factor # summary()의 결과에서 coef의 순서는 Intercept : 0, tv : 1, radio : 2 print(variance_inflation_factor(advdf.values, 1)) # tv : 12.570312383503682 print(variance_inflation_factor(advdf.values, 2)) # radio : 3.1534983754953845 # 데이터 프레임으로 꺼내서 보기 vifdf = pd.DataFrame() vifdf['vif_value'] = [variance_inflation_factor(advdf.values, i) for i in range(1,3)] print(vifdf) print("참고 : Cook's distance - 극단값(이상치)를 나타내는 지표") from statsmodels.stats.outliers_influence import OLSInfluence cd, _ = OLSInfluence(lm_mul).cooks_distance print(cd.sort_values(ascending = False).head()) import statsmodels.api as sm sm.graphics.influence_plot(lm_mul, criterion = 'cooks') plt.show() print(advdf.iloc[[130, 5, 35, 178, 126]]) # 이상치 데이터로 의심됨으로 제거를 권장 <console> tv radio newspaper sales 0 230.1 37.8 69.2 22.1 1 44.5 39.3 45.1 10.4 2 17.2 45.9 69.3 9.3 (200, 4) <class 'pandas.core.frame.DataFrame'> RangeIndex: 200 entries, 0 to 199 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 tv 200 non-null float64 1 radio 200 non-null float64 2 newspaper 200 non-null float64 3 sales 200 non-null float64 dtypes: float64(4) memory usage: 6.4 KB None 상관계수(r) : tv sales tv 1.000000 0.782224 sales 0.782224 1.000000 OLS Regression Results ============================================================================== Dep. Variable: sales R-squared: 0.612 Model: OLS Adj. R-squared: 0.610 Method: Least Squares F-statistic: 312.1 Date: Wed, 16 Nov 2022 Prob (F-statistic): 1.47e-42 Time: 11:05:29 Log-Likelihood: -519.05 No. Observations: 200 AIC: 1042. Df Residuals: 198 BIC: 1049. Df Model: 1 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ Intercept 7.0326 0.458 15.360 0.000 6.130 7.935 tv 0.0475 0.003 17.668 0.000 0.042 0.053 ============================================================================== Omnibus: 0.531 Durbin-Watson: 1.935 Prob(Omnibus): 0.767 Jarque-Bera (JB): 0.669 Skew: -0.089 Prob(JB): 0.716 Kurtosis: 2.779 Cond. No. 338. ============================================================================== 예측 결과 : [17.97077451 9.14797405 11.78625759] --------- tv radio newspaper sales tv 1.000000 0.054809 0.056648 0.782224 radio 0.054809 1.000000 0.354104 0.576223 newspaper 0.056648 0.354104 1.000000 0.228299 sales 0.782224 0.576223 0.228299 1.000000 OLS Regression Results ============================================================================== Dep. Variable: sales R-squared: 0.897 Model: OLS Adj. R-squared: 0.896 Method: Least Squares F-statistic: 859.6 Date: Wed, 16 Nov 2022 Prob (F-statistic): 4.83e-98 Time: 11:05:29 Log-Likelihood: -386.20 No. Observations: 200 AIC: 778.4 Df Residuals: 197 BIC: 788.3 Df Model: 2 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ Intercept 2.9211 0.294 9.919 0.000 2.340 3.502 tv 0.0458 0.001 32.909 0.000 0.043 0.048 radio 0.1880 0.008 23.382 0.000 0.172 0.204 ============================================================================== Omnibus: 60.022 Durbin-Watson: 2.081 Prob(Omnibus): 0.000 Jarque-Bera (JB): 148.679 Skew: -1.323 Prob(JB): 5.19e-33 Kurtosis: 6.292 Cond. No. 425. ============================================================================== 예측 결과 : [19.08910967 12.47695825 16.89629275] ---------------- residual : 0 1.544535 1 -1.945362 2 -3.037018 dtype: float64 5.511147094239277e-15 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 특정한 패턴을 가지면 좋지 않다. 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다. shapiro test : ShapiroResult(statistic=0.9180378317832947, pvalue=4.190036317908152e-09) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다. 잔차가 독립적이어야 한다.(자기상관이 없어야 된다.) 등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다. 다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다. 12.570312383503682 3.1534983754953845 vif_value 0 12.570312 1 3.153498 참고 : Cook's distance - 극단값(이상치)를 나타내는 지표 130 0.258065 5 0.123721 35 0.063065 178 0.061401 126 0.048958 dtype: float64 tv radio newspaper sales 130 0.7 39.6 8.7 1.6 5 8.7 48.9 75.0 7.2 35 290.7 4.1 8.5 12.8 178 276.7 2.3 23.7 11.8 126 7.8 38.9 50.6 6.6newspaper 가 독립변수로서 맞지 않지만, 바로 빼는 것이 아닌, 여러가지 요인을 두고 검토를 해 봐야한다.
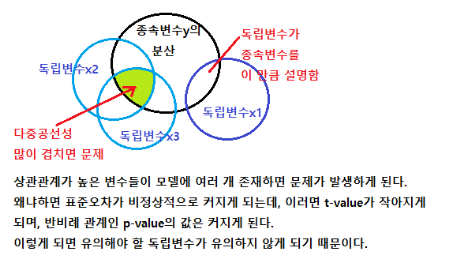
회귀분석모형의 적절성을 위한 조건 : 아래의 조건 위배 시에는 변수 제거나 조정을 신중히 고려해야 함.
1) 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다.
2) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다.
3) 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 일정한 패턴을 가지면 좋지 않다.
4) 등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다.
5) 다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다.
예) 나이와 학년이 신체 구조에 미치는 영향(교집합이 매우 커 다중공선성 우려). 아래 그림 참조.

tv, sales 의 관계 시각화 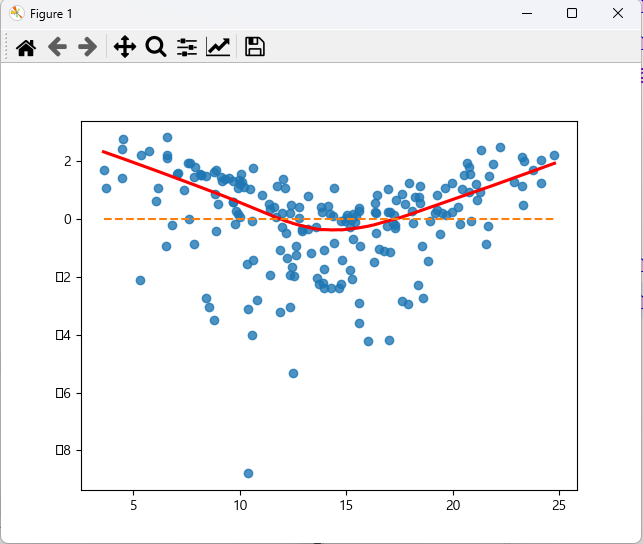
잔차항 시각화 잔차는 0에 가까울 수록 좋다. 위의 데이터는 잔차항이 선형성을 만족하지 못 한다. 그럴 경우에는 다항회귀를 추천한다.
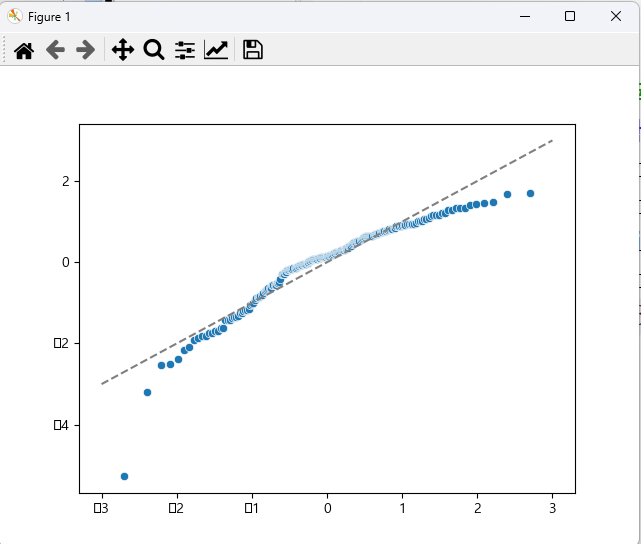
정규성 확인 선이 선형이어야 되며 점선을 따라 움직여야 된다. 위의 그래프는 점선에서 벗어나기 때문에 정규성 만족이 아니다.
log를 취하는 듯의 작업을 통해 정규분포를 따르도록 데이터 가공 작업 필요하다.

일정한 패턴의 곡선을 그리므로 등분산성을 만족하지 못함
이상값 확인, 비선형인지 확인, 정규성을 확인
만약에 정규성은 만족하나 등분산성을 만족하지 못하는 경우에는 가중회귀분석을 추천한다.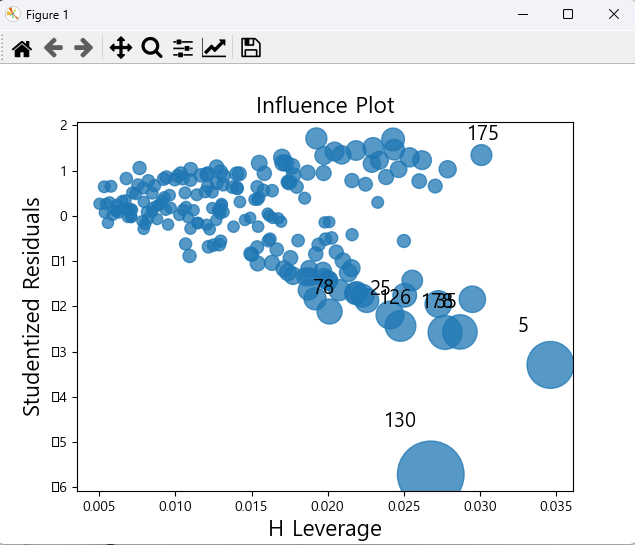
극단값(이상치)를 나타내는 지표 원이 크면 클수록 이상치를 의심한다. 이상치 데이터로 의심됨으로 제거를 권장한다.
'Python 데이터 분석' 카테고리의 다른 글
Python 데이터분석 기초 51 - 선형회귀분석 모델 LinearRegression을 사용 - summary() 함수 지원 X (0) 2022.11.16 회귀분석모형의 적절성을 위한 5가지 조건 예제 (1) 2022.11.16 단순선형회귀, 다중선형회귀 예제 (0) 2022.11.15 Python 데이터분석 기초 50 - 귀납적 추론, 연역적 추론, 단순선형회귀 예제(mtcars), 키보드로 값 받기 (0) 2022.11.15 단회귀분석(선형회귀분석) OLS 예제(iris dataset으로 모델 생성) (0) 2022.11.15