-
TensorFlow 기초 31 - 워드 임베딩 vs 원핫 인코딩, 밀집표현, 단어 간 유사도TensorFlow 2022. 12. 9. 15:06
자연어 처리란 자연어의 의미를 분석하여 컴퓨터를 통해 사람들이 원하는 어떤 결과를 처리할 수 있도록 하는 일을 말한다.
이를 통해 음성 인식, 문서 요약, 문서 번역, 감성 분석, 텍스트 분류(스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇 등의 다양한 분야에서 사용될 수 있다. 딥 러닝을 이용한 자연어 처리가 주목을 받으면서, 획기적인 알고리즘으로 무장한 새로운 연구 논문들이 활발하게 발표되고 있다. 이러한 기술들을 이해하려면 먼저 자연어 처리에 필요한 전처리 방법(preprocessing), 전통적인 방식의 통계 기반 언어모델, 그리고 무엇보다 중요한 것은 자연어 처리를 위한 관심이 필요하다고 생각한다.
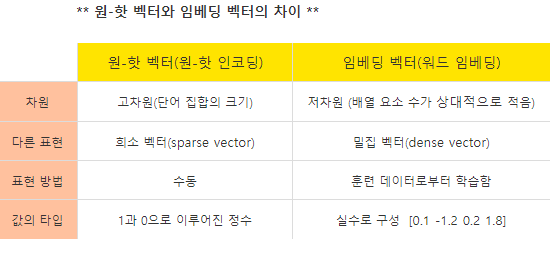
워드 임베딩 : 단어를 수치화해서 vector로 만듦, 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법
1) 카테고리컬 인코딩 : 원핫인코딩, 희소 벡터2) 밀집표현 : 다차원 벡터 생성
출처 = https://cafe.daum.net/flowlife/S2Ul/19 # 데이터 인코딩 print('레이블 인코딩') datas = ['python', 'program', 'computer', 'lan', 'say'] values =[] for x in range(len(datas)): values.append(x) print(values, ' ', type(values)) print('원핫 인코딩') import numpy as np onehot = np.eye(len(datas)) print(onehot) print('\n인코딩 클래스를 사용') from sklearn.preprocessing import LabelEncoder datas = ['python', 'program', 'computer', 'lan', 'say'] encoder = LabelEncoder().fit(datas) values = encoder.transform(datas) print(values, type(values)) print(encoder.classes_) print('밀집표현 : 단어의 의미를 다차원 공간에 실수로 벡터화 하는 분산표현 방법. 단어 간 유사성을 표현할 수 있다.') from gensim.models import word2vec sentence = [['python', 'program', 'computer', 'lan', 'say']] model = word2vec.Word2Vec() sentece = [['python', 'program', 'computer', 'lan', 'say']] # Word2Vec을 이용 : 유사한 단어들을 비슷한 방향과 힘의 벡터를 갖도록 변환하여 사용하는 방법 model = word2vec.Word2Vec(sentence, min_count=1, vector_size=50) print(model) word_vectors = model.wv # 단어 벡터 생성 print('word_vectors :', word_vectors) # KeyedVectors object print('word_vectors index :', word_vectors.key_to_index) print('word_vectors keys :', word_vectors.key_to_index.keys()) print('word_vectors values :', word_vectors.key_to_index.values()) vocabs = word_vectors.key_to_index.keys() word_vectors_list = [word_vectors[v] for v in vocabs] print(word_vectors_list[0], ' ', word_vectors_list[1]) # 단어 간 유사도 print(word_vectors.similarity(w1='python', w2='computer')) print(word_vectors.similarity(w1='python', w2='say')) print(word_vectors.most_similar(positive='computer')) # 코사인 유사도 알고리즘 이용 : -1 ~0 ~1 절대값 1에 근사 # 단어 간 유사도 시각화 import matplotlib.pyplot as plt def plot_2d(vocabs, x, y): plt.figure(figsize = (8, 6)) plt.scatter(x, y) for i, v in enumerate(vocabs): plt.annotate(v, xy=(x[i], y[i])) from sklearn.decomposition import PCA pca = PCA(n_components=2) xys = pca.fit_transform(word_vectors_list) xs = xys[:, 0] ys = xys[:, 1] plot_2d(vocabs, xs, ys) plt.show() <console> 레이블 인코딩 [0, 1, 2, 3, 4] <class 'list'> 원핫 인코딩 [[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 1. 0.] [0. 0. 0. 0. 1.]] 인코딩 클래스를 사용 [3 2 0 1 4] <class 'numpy.ndarray'> ['computer' 'lan' 'program' 'python' 'say'] 밀집표현 : 단어의 의미를 다차원 공간에 실수로 벡터화 하는 분산표현 방법. 단어 간 유사성을 표현할 수 있다. Word2Vec(vocab=5, vector_size=50, alpha=0.025) word_vectors : <gensim.models.keyedvectors.KeyedVectors object at 0x00000259CD549D60> word_vectors index : {'say': 0, 'lan': 1, 'computer': 2, 'program': 3, 'python': 4} word_vectors keys : dict_keys(['say', 'lan', 'computer', 'program', 'python']) word_vectors values : dict_values([0, 1, 2, 3, 4]) [-1.0724545e-03 4.7286032e-04 1.0206699e-02 1.8018546e-02 -1.8605899e-02 -1.4233618e-02 1.2917743e-02 1.7945977e-02 -1.0030856e-02 -7.5267460e-03 1.4761009e-02 -3.0669451e-03 -9.0732286e-03 1.3108101e-02 -9.7203208e-03 -3.6320353e-03 5.7531595e-03 1.9837476e-03 -1.6570430e-02 -1.8897638e-02 1.4623532e-02 1.0140524e-02 1.3515387e-02 1.5257311e-03 1.2701779e-02 -6.8107317e-03 -1.8928051e-03 1.1537147e-02 -1.5043277e-02 -7.8722099e-03 -1.5023164e-02 -1.8600845e-03 1.9076237e-02 -1.4638334e-02 -4.6675396e-03 -3.8754845e-03 1.6154870e-02 -1.1861792e-02 9.0322494e-05 -9.5074698e-03 -1.9207101e-02 1.0014586e-02 -1.7519174e-02 -8.7836506e-03 -7.0199967e-05 -5.9236528e-04 -1.5322480e-02 1.9229483e-02 9.9641131e-03 1.8466286e-02] [-0.01631584 0.00899159 -0.00827415 0.00164907 0.01699724 -0.00892436 0.009035 -0.01357392 -0.00709698 0.01879702 -0.00315531 0.00064274 -0.00828126 -0.01536538 -0.00301602 0.00493959 -0.00177606 0.01106732 -0.00548595 0.00452013 0.01091159 0.0166919 -0.00290748 -0.01841629 0.0087411 0.00114357 0.01488381 -0.00162657 -0.00527683 -0.01750602 -0.00171311 0.00565312 0.01080286 0.01410531 -0.01140625 0.00371764 0.01217772 -0.0095961 -0.00621452 0.01359526 0.00326295 0.00037983 0.00694727 0.00043555 0.01923765 0.01012121 -0.01783478 -0.01408312 0.00180291 0.01278507] 0.1656355 -0.11821285 [('python', 0.16563549637794495), ('say', 0.1267007291316986), ('lan', 0.011071926914155483), ('program', -0.1551557034254074)]단어와 단어 사이의 관계를 수치로 표현할 수 있다.

단어 간 유사도 시각화 'TensorFlow' 카테고리의 다른 글
TensorFlow 기초 33 - sklearn이 제공하는 자연어 특징 추출 : 문자열을 수치 벡터화 (0) 2022.12.13 TensorFlow 기초 32 - 형태소 분석 후 word2vec을 이용하여 단어 간 유사도 확인 (0) 2022.12.09 TensorFlow 기초 30-1 - 전이학습(기초 30 이어서) (0) 2022.12.08 TensorFlow 기초 30 - cnn을 통한 댕댕이와 냥이 분류 모델 (0) 2022.12.08 TensorFlow 기초 29 - CNN을 활용해 이미지 특징을 뽑아 Dense로 학습(컬러 사) (0) 2022.12.08