-
TensorFlow 기초 6 - Keras 모델 기본 개념, 케라스 모델링 순서TensorFlow 2022. 11. 29. 11:35
케라스 모델링 순서(데이터 셋 > 모델 구성 > 모델 학습 과정 설정 > 모델 학습 > 모델 평가 > 모델 사용
Keras 기본 개념
- 케라스의 가장 핵심적인 데이터 구조는 "모델" 이다.
- 케라스에서 제공하는 시퀀스 모델을 이용하여 레이어를 순차적으로 쉽게 쌓을 수 있다.
- 케라스는 Sequential에 Dense 레이어(fully-connected layers 완전히 연결된 레이어)를 쌓는 스택 구조를 사용한다.
케라스 모델링 순서
1. 데이터 셋 생성
원본 데이터를 불러오거나 데이터를 생성한다.
데이터로부터 훈련셋, 검증셋, 시험셋을 생성한다. 이 때 딥러닝 모델의 학습 및 평가를 할 수 있도록 포맷 변환을 한다.
2. 모델 구성
시퀀스 모델을 생성한 뒤 필요한 레이어를 추가하며 구성한다. 좀 더 복잡한 모델이 필요할 때는 케라스 함수 API를 이용한다.
예)
from keras.models import Sequential
from keras.layers import Dense
Dense()의 주요 인자를 보자.
첫번째 인자 = 출력 뉴런의 수.
input_dim = 입력 뉴런의 수. (입력의 차원)
init = 가중치 초기화 방법.
- uniform : 균일 분포
- normal : 가우시안 분포
activation = 활성화 함수. https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339
- linear : 디폴트 값으로 별도 활성화 함수 없이 입력 뉴런과 가중치의 계산 결과 그대로 출력. Ex) 선형 회귀
- sigmoid : 이진 분류 문제에서 출력층에 주로 사용되는 활성화 함수.
- softmax : 셋 이상을 분류하는 다중 클래스 분류 문제에서 출력층에 주로 사용되는 활성화 함수.
- relu : 은닉층에 주로 사용되는 활성화 함수.
3. 모델 학습 과정 설정
학습하기 전, 학습에 대한 설정을 수행한다. 손실 함수 및 최적화 방법을 정의. compile() 함수를 사용한다.
예1) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
위 코드는 임베딩층, 은닉층, 출력층을 추가하여 모델을 설계한 후에, 마지막으로 컴파일 하는 과정을 진행한다.
속성 : optimizer : 훈련 과정을 설정하는 옵티마이저를 설정. 'adam'이나 'sgd'와 같이 문자열로 지정할 수도 있다.
SGD()(with or without momentum), RMSprop(), Adam() etc.
loss : 훈련 과정에서 사용할 손실 함수(loss function)를 설정.
metrics : 훈련을 모니터링 하기 위한 지표를 선택.
예2) model.compile(optimizer=tf.keras.optimizers.RMSprop(0.01),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=[tf.keras.metrics.CategoricalAccuracy()])
참고 : 경사하강법 https://velog.io/@arittung/DeepLearningStudyDay8
- Momentum
Momentum은 관성이라는 물리학의 법칙을 응용한 방법으로 모멘텀 SGD는 경사 하강법에 관성을 더 해준다. 모멘텀은 SGD에서 계산된 접선의 기울기에 한 시점(step) 전의 접선의 기울기 값을 일정한 비율만큼 반영한다. 이렇게 하면 로컬 미니멈(Local minimum)에 빠지더라도 관성의 힘으로 넘어서는 효과를 줄 수 있다.
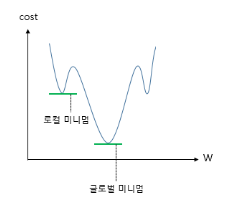
다시 말해 로컬 미니멈에 도달하였을 때, 기울기가 0이라서 기존의 경사 하강법이라면 이를 글로벌 미니멈으로 잘못 인식하여 계산이 끝났을 상황이라도 모멘텀. 즉, 관성의 힘을 빌리면 값이 조절되면서 로컬 미니멈에서 탈출하는 효과를 얻을 수도 있다.
- RMSprop
Adagrad는 학습을 계속 진행한 경우에는, 나중에 가서는 학습률이 지나치게 떨어진다는 단점이 있는데 이를 다른 수식으로 대체하여 이러한 단점을 개선하였다.
- Adam
Momentum과 RMSprop의 장점을 이용한 방법으로, 방향과 학습률 두 가지를 모두 처리할 수 있다.
4. 모델 학습시키기
훈련셋을 이용하여 구성한 모델로 학습 시킨다. fit() 함수를 사용한다.
예) model.fit(X_train, y_train, epochs=10, batch_size=32)
속성 :
첫번째 인자 = 훈련 데이터에 해당됨.
두번째 인자 = 지도 학습 관점에서 레이블 데이터에 해당됨.
epochs = 에포크 1은 전체 데이터를 한 차례 훑고 지나갔음을 의미함. 정수값 기재 필요. 총 훈련 횟수를 정의함.
batch_size = 기본값은 32. 미니 배치 경사 하강법을 사용하고 싶지 않을 경우에는 batch_size=None을 통해 선택 가능.
5. 모델 평가
준비된 시험셋으로 학습한 모델을 평가한다. evaluate() 함수를 사용
예) model.evaluate(X_test, y_test, batch_size=32)
속성 : 첫번째 인자 = 테스트 데이터에 해당됨.
두번째 인자 = 지도 학습 관점에서 레이블 테스트 데이터에 해당됨.
batch_size = 배치 크기.
6. 모델 사용하기
임의의 입력으로 모델의 출력을 얻는다. predict() 함수를 사용한다.
예) model.predict(X_input, batch_size=32)
속성 : 첫번째 인자 = 예측하고자 하는 데이터.
batch_size = 배치 크기.
출처 = https://cafe.daum.net/flowlife/S2Ul/10
# Keras 라이브러리(모듈)로 모델 생성 네트워크 구성하기 # Keras 기본 개념 # - 케라스의 가장 핵심적인 데이터 구조는 "모델" 이다. # - 케라스에서 제공하는 시퀀스 모델을 이용하여 레이어를 순차적으로 쉽게 쌓을 수 있다. # - 케라스는 Sequential에 Dense 레이어(fully-connected layers 완전히 연결된 레이어)를 쌓는 스택 구조를 사용한다. import numpy as np import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Activation from keras.optimizers import SGD, RMSprop, Adam # 논리회로 분류 모델 생성 # 1) 데이터 수집 및 가공 x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) print(x) y = np.array([0, 1, 1, 1]) # or [[0, 1, 1, 1]] # 2) 모델 네트워크 구성 # 시퀀스 모델을 생성한 뒤 필요한 레이어를 추가하며 구성한다. # model = Sequential() # model.add(Dense(units=1, input_dim=2)) # 2개의 데이터가 들어와서 1개로 빠져나간다. # model.add(Activation('sigmoid')) # 활성화 함수는 sigmoid 사용, 0 ~ 1의 실수값으로 분류 model = Sequential([ Dense(units=1, input_dim=2), Activation('sigmoid') # 3개 이상의 데이터가 들어온다면 softmax 사용 가능 ]) # 3) 모델 학습 과정 설정 # 학습하기 전, 학습에 대한 설정을 수행한다. 손실 함수 및 최적화 방법을 정의. compile() 함수를 사용한다. # model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy']) # model.compile(optimizer=SGD(learning_rate=0.01, momentum=0.9), loss='binary_crossentropy', metrics=['accuracy']) # model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) # model.compile(optimizer=RMSprop(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy']) # model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.compile(optimizer=Adam(learning_rate=0.01), loss='binary_crossentropy', metrics=['accuracy']) # sgd = 확률적 경사 하강법 # 4) 모델 학습시키기 - ML에서 학습이란 더 나은 표현(출력)을 찾는 자동화 과정이다. # 훈련셋을 이용하여 구성한 모델로 학습 시킨다. fit() 함수를 사용한다. model.fit(x=x, y=y, batch_size=1, epochs=1000, verbose=0) # epochs = n번 학습하라는 의미 # 5) 모델 평가 # 준비된 시험셋으로 학습한 모델을 평가한다. evaluate() 함수를 사용 loss_metrics = model.evaluate(x, y, batch_size=1, verbose=0) print('loss_metrics :', loss_metrics) # [0.7650536894798279, 0.5] [loss, accuracy] # 6) 모델 사용하기 - 예측값 출력 # 임의의 입력으로 모델의 출력을 얻는다. predict() 함수를 사용한다. pred = model.predict(x, batch_size=1, verbose=0) print('pred :', pred) print('pred :', pred.flatten()) # faltten은 차원 축소 함수 pred = (model.predict(x) > 0.5).astype('int32') print('pred :', pred) # 7) 최적의 모델인 경우 저장 model.save('tf5.hdf5') del model from keras.models import load_model model = load_model('tf5.hdf5') pred = (model.predict(x) > 0.5).astype('int32') print('pred :', pred) <console> [[0 0] [0 1] [1 0] [1 1]] loss_metrics : [0.013656261377036572, 1.0] pred : [[0.03479036] [0.9879211 ] [0.9929653 ] [0.9999969 ]] pred : [0.03479036 0.9879211 0.9929653 0.9999969 ] 1/1 [==============================] - ETA: 0s 1/1 [==============================] - 0s 22ms/step pred : [[0] [1] [1] [1]] 1/1 [==============================] - ETA: 0s 1/1 [==============================] - 0s 20ms/step pred : [[0] [1] [1] [1]]모델 학습 과정 설정에서 최근에는 Adam을 많이 쓰지만 데이터에 따라서 SGD나 RMSprop를 사용해야 될 경우가 있다.

'TensorFlow' 카테고리의 다른 글
TensorFlow 기초 8 - cost와 w(기울기) 구하기(함수 사용 x - 원리 이해) (0) 2022.11.29 TensorFlow 기초 7 - Keras XOR(복수의 뉴런(노드)를 사용) (0) 2022.11.29 TensorFlow 기초 5 - 사칙연산, 관계연산, 논리연산, 차원 축소, 차원 확대, one-hot, argmax (1) 2022.11.28 TensorFlow 기초 4 - 사칙연산, tf.constant(), tf.Variable(), autograph 기능 (0) 2022.11.28 TensorFlow 기초 3 - TF의 구조 (Graph로 설계된 내용은 Session에 실행) (0) 2022.11.28