-
Python 데이터분석 기초 75 - K-means Clustering(비계층적 군집분석)Python 데이터 분석 2022. 11. 25. 17:12
비계층적 군집분석
군집의 수를 정한 상태에서 설정된 군집의 중심에서 가장 가까운 개체를 하나씩 포함해 나가는 방법으로 많은 자료를 빠르고 쉽게 분류할 수 있지만 군집의 수를 미리 정해 줘야 하고 군집을 형성하기 위한 초기값에 따라 군집의 결과가 달라진다는 어려움이 있기 때문에 계층적 군집분석을 통해 대략적인 군집의 수를 파악하고 이를 초기 군집 수로 설정한다
K-means Clustering
군집화는 아무런 정보가 없는 상태에서 데이터를 분류하는 방법이다. K-means Clustering 이란 데이터 분류 종류를 K개 라고 했을 때 입력한 데이터 중 임의로 선택된 K 개의 기준과 각 점들의 거리를 오차로 생각하고 각각의 점들은 거리가 가장 가까운 기준에 해당한다고 생각하는 것이다. 그리고 이제 각각 기준에 해당하는 점들 모두의 평균을 새로운 기준으로 갱신해 나가게 된다. 이렇게 해서 가장 적절한 중심점들을 찾는 것이다. 이렇게 학습을 반복하면 데이터를 분류할 수 있게 된다.
클러스터링은 보통 4개의 유형으로 구분된다
- 클러스터 중심(centroid) 또는 평균 기반 클러스터링 k-means
- 빈도수가 많은 중간점(medoid) 기반 클러스터링 k-medoids
- 계층적 클러스터링
- 밀도 기반 클러스터링
# 비계층적 군집분석 : # 군집의 수를 정한 상태에서 설정된 군집의 중심에서 가장 가까운 개체를 하나씩 포함해 나가는 방법으로 # 많은 자료를 빠르고 쉽게 분류할 수 있지만 군집의 수를 미리 정해 줘야 하고 군집을 형성하기 위한 # 초기값에 따라 군집의 결과가 달라진다는 어려움이 있기 때문에 계층적 군집분석을 통해 대략적인 군집의 # 수를 파악하고 이를 초기 군집 수로 설정한다. # 방법: k-means clustering import matplotlib.pyplot as plt from sklearn.datasets import make_blobs x, y = make_blobs(n_samples = 150, n_features = 2, centers = 3, cluster_std = 0.5, shuffle = True, random_state = 0) print(x[:3]) # n_features = 차원 # print(y) 군집분석이므로 의미 없다. # plt.scatter(x[:, 0], x[:, 1], s=50, c='gray', marker='o') # plt.grid(True) # plt.show() from sklearn.cluster import KMeans # 비계층적 군집분석 중 가장 많이 사용(데이터의 분포가 비선형인 경우 정확도가 떨어진다.) # 최초의 군집 중심점을 설정하는 방법 # init_centroid = 'random' init_centroid = 'k-means++' # 기본값 kmodel = KMeans(n_clusters=3, init = init_centroid, random_state = 0) pred = kmodel.fit_predict(x) print(pred) print(x[pred == 0][:3]) print(x[pred == 1][:3]) print(x[pred == 2][:3]) print('centroid(군집 중심점) :\n', kmodel.cluster_centers_) plt.scatter(x[pred == 0, 0], x[pred == 0, 1], s=50, c='red', marker='o', label = 'cluster1') plt.scatter(x[pred == 1, 0], x[pred == 1, 1], s=50, c='green', marker='s', label = 'cluster2') plt.scatter(x[pred == 2, 0], x[pred == 2, 1], s=50, c='blue', marker='v', label = 'cluster3') plt.scatter(kmodel.cluster_centers_[:, 0], kmodel.cluster_centers_[:, 1], s=70, c='black', marker='+', label = 'center') # 중심점 plt.grid(True) plt.legend() plt.show() # K-Means에서 K를 정하는 것이 가장 중요한 문제 중 하나이다. # 방법 1 : 계층적 군집으로 K값 유추 # 방법 2 : 엘보우(elbow) 기법 - 클러스터 간 SSE의 차이를 이용 def elbow(x): sse = [] for i in range(2, 11): km = KMeans(n_clusters=i, init = init_centroid, random_state = 0).fit(x) sse.append(km.inertia_) plt.plot(range(2, 11), sse, marker='o') plt.xlabel('count of cluster') plt.ylabel('SSE') plt.show() elbow(x) # 방법 3 : 실루엣(silhouette) 기법 - 클러스터 간 실루엣 계수값을 수평 막대 그래프로 표현 ''' 실루엣(silhouette) 기법 클러스터링의 품질을 정량적으로 계산해 주는 방법이다. 클러스터의 개수가 최적화되어 있으면 실루엣 계수의 값은 1에 가까운 값이 된다. 실루엣 기법은 k-means 클러스터링 기법 이외에 다른 클러스터링에도 적용이 가능하다 ''' import numpy as np from sklearn.metrics import silhouette_samples from matplotlib import cm # 데이터 X와 X를 임의의 클러스터 개수로 계산한 k-means 결과인 y_km을 인자로 받아 각 클러스터에 속하는 데이터의 실루엣 계수값을 수평 막대 그래프로 그려주는 함수를 작성함. # y_km의 고유값을 멤버로 하는 numpy 배열을 cluster_labels에 저장. y_km의 고유값 개수는 클러스터의 개수와 동일함. def plotSilhouette(x, pred): cluster_labels = np.unique(pred) n_clusters = cluster_labels.shape[0] # 클러스터 개수를 n_clusters에 저장 sil_val = silhouette_samples(x, pred, metric='euclidean') # 실루엣 계수를 계산 y_ax_lower, y_ax_upper = 0, 0 yticks = [] for i, c in enumerate(cluster_labels): # 각 클러스터에 속하는 데이터들에 대한 실루엣 값을 수평 막대 그래프로 그려주기 c_sil_value = sil_val[pred == c] c_sil_value.sort() y_ax_upper += len(c_sil_value) plt.barh(range(y_ax_lower, y_ax_upper), c_sil_value, height=1.0, edgecolor='none') yticks.append((y_ax_lower + y_ax_upper) / 2) y_ax_lower += len(c_sil_value) sil_avg = np.mean(sil_val) # 평균 저장 plt.axvline(sil_avg, color='red', linestyle='--') # 계산된 실루엣 계수의 평균값을 빨간 점선으로 표시 plt.yticks(yticks, cluster_labels + 1) plt.ylabel('클러스터') plt.xlabel('실루엣 개수') plt.show() ''' 그래프를 보면 클러스터 1~3 에 속하는 데이터들의 실루엣 계수가 0으로 된 값이 아무것도 없으며, 실루엣 계수의 평균이 0.7 보다 크므로 잘 분류된 결과라 볼 수 있다. ''' X, y = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=0.5, shuffle=True, random_state=0) km = KMeans(n_clusters=3, random_state=0) y_km = km.fit_predict(X) plotSilhouette(X, y_km) <console> [[2.60509732 1.22529553] [0.5323772 3.31338909] [0.802314 4.38196181]] [0 2 2 2 0 2 2 0 1 2 0 1 1 2 2 1 1 0 1 0 2 0 2 2 1 0 0 2 1 0 1 1 1 1 2 0 0 0 2 2 1 1 2 0 0 0 1 2 1 2 0 2 2 0 0 1 2 0 1 2 1 1 1 1 2 1 2 0 2 2 2 0 0 2 0 2 2 1 1 2 0 0 2 2 0 0 0 1 1 0 0 2 0 2 0 2 1 1 0 0 0 0 1 0 0 2 1 2 2 2 1 2 0 1 2 1 2 2 1 1 2 0 2 2 0 0 1 0 1 1 1 1 0 1 1 1 2 1 0 1 2 2 0 0 1 1 1 1 0 0] [[2.60509732 1.22529553] [2.61858548 0.35769791] [2.37533328 0.08918564]] [[-2.12133364 2.66447408] [-0.37494566 2.38787435] [-1.84562253 2.71924635]] [[0.5323772 3.31338909] [0.802314 4.38196181] [0.5285368 4.49723858]] centroid(군집 중심점) : [[ 2.06521743 0.96137409] [-1.5947298 2.92236966] [ 0.9329651 4.35420712]]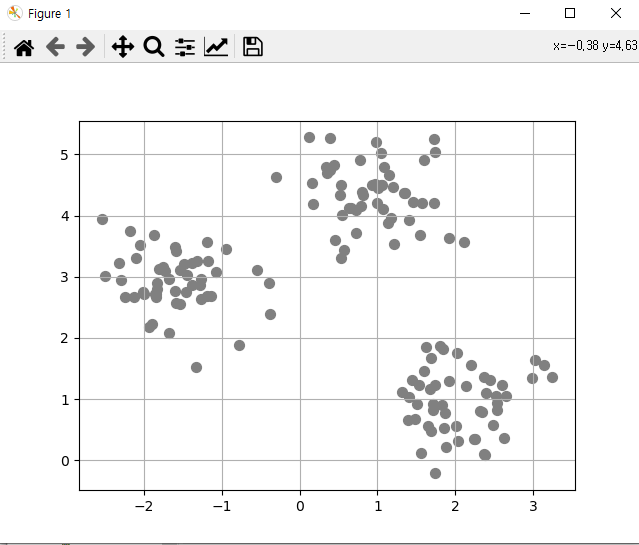
x 데이터의 시각화 
중심점 시각화 K-Means에서 K를 정하는 것이 가장 중요한 문제 중 하나이다.
방법 1 : 계층적 군집으로 K값 유추
방법 2 : 엘보우(elbow) 기법 - 클러스터 간 SSE의 차이를 이용방법 3 : 실루엣(silhouette) 기법 - 클러스터 간 실루엣 계수값을 수평 막대 그래프로 표현
실루엣(silhouette) 기법
클러스터링의 품질을 정량적으로 계산해 주는 방법이다.
클러스터의 개수가 최적화되어 있으면 실루엣 계수의 값은 1에 가까운 값이 된다.
실루엣 기법은 k-means 클러스터링 기법 이외에 다른 클러스터링에도 적용이 가능하다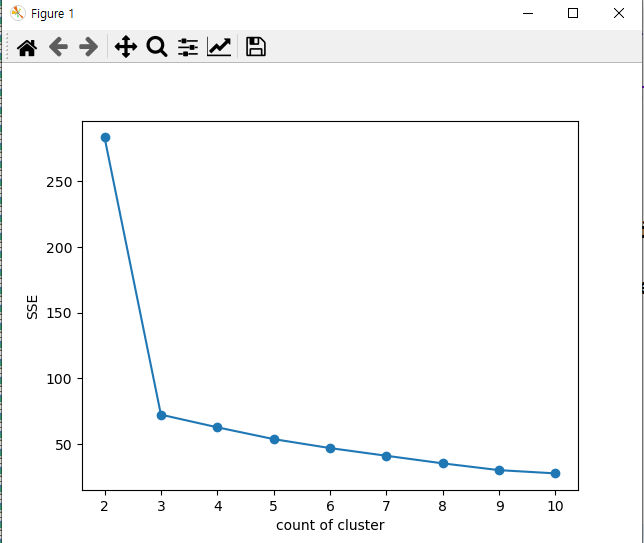
엘보우(elbow) 기법 시각화 급격하게 떨어지는데 완만해지는 지점 즉, 3이 K값으로 볼 수 있다.

실루엣 기법 시각화 갯수가 3개 나오므로 K값으로 3을 넣을 수 있다.
실루엣 기법 참고
Daum 카페
cafe.daum.net
'Python 데이터 분석' 카테고리의 다른 글
Python 데이터분석 기초 76 - 밀도 기반 클러스터링(DBSCAN) (0) 2022.11.28 iris dataset으로 지도학습(KNN) / 비지도학습(K-Means) 비교 (1) 2022.11.25 Python 데이터분석 기초 74 - Clustering(군집화) - 계층 군집분석 - data(iris) (0) 2022.11.25 Python 데이터분석 기초 73 - Clustering(군집화) - 비계층 군집분석 (0) 2022.11.25 MLP(multi-layer perceptron) - 다층 신경망 예제, breast_cancer dataset, 표준화 (0) 2022.11.25