-
Python 데이터분석 기초 33 - 실습 예제 2, 3,4) 단일 표본 t 검정 (one-sample t- test)Python 데이터 분석 2022. 11. 7. 17:45
실습 예제 2)
# 실습 예제 2) 단일표본 t 검정 (one-sample t-test) # 귀무 : 어느 한 집단의 자료들 평균은 0이다. # 대립 : 어느 한 집단의 자료들 평균은 0이 아니다. np.random.seed(1) mu = 0 n = 10 x = stats.norm(mu).rvs(n) # 랜덤한 데이터 10개 생성 print(x, np.array(x).mean()) # -0.0971408 # sns.displot(x, kde=True, rug = True) # kde = 선, rug = 밑의 그래프 # plt.show() result2 = stats.ttest_1samp(x, popmean = mu) # result2 = stats.ttest_1samp(x, popmean = 0.9) print('result2 : statistic(t-value) : {}, p-value : {}'.format(result2[0], result2[1])) # 해석 : p-value : 0.8121703589172078 > 0.05 이므로 귀무가설 채택. 어느 한 집단의 자료들 평균은 0이다. <console> [ 1.62434536 -0.61175641 -0.52817175 -1.07296862 0.86540763 -2.3015387 1.74481176 -0.7612069 0.3190391 -0.24937038] -0.09714089080609985 result2 : statistic(t-value) : -2.511903862200501, p-value : 0.033206859534901594실습 예제 3)
하나의 집단에 대한 표본평균이, 예측된 평균과 차이가 있는지 검증
# 실습 예제 3) # A중학교 1학년 1반 학생들의 시험결과가 담긴 파일을 읽어 처리 (국어 점수 평균검정) student.csv # 귀무 : A중학교 1학년 1반 학생들의 국어 점수 평균은 80이다. # 대립 : A중학교 1학년 1반 학생들의 국어 점수 평균은 80이 아니다. data = pd.read_csv('../testdata/student.csv') print(data.head(3)) # 집단이 국어 하나이다. print(data.국어.mean()) # 72.9 vs 80.0 차이? result3 = stats.ttest_1samp(data.국어, popmean = 80) print('result3 : statistic(t-value) : {}, p-value : {}'.format(result3[0], result3[1])) # 해석 : p-value : 0.19856051824785262 > 0.05 이므로 귀무가설 채택. A중학교 1학년 1반 학생들의 국어 점수 평균은 80이다. <console> 이름 국어 영어 수학 0 박치기 90 85 55 1 홍길동 70 65 80 2 김치국 92 95 76 72.9 result3 : statistic(t-value) : -1.3321801667713213, p-value : 0.19856051824785262실습 예제 4)
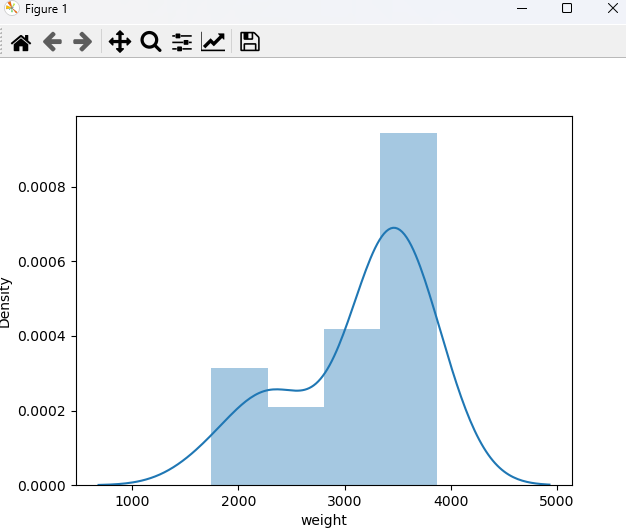
여아 신생아 몸무게의 평균 검정 수행 babyboom.csv 여아 신생아의 몸무게는 평균이 2800(g)으로 알려져 왔으나 이보다 더 크다는 주장이 나왔다. 표본으로 여아 18명을 뽑아 체중을 측정하였다고 할 때 새로운 주장이 맞는지 검정해 보자.
# 실습 예제 4) # 여아 신생아 몸무게의 평균 검정 수행 babyboom.csv # 여아 신생아의 몸무게는 평균이 2800(g)으로 알려져 왔으나 이보다 더 크다는 주장이 나왔다. # 표본으로 여아 18명을 뽑아 체중을 측정하였다고 할 때 새로운 주장이 맞는지 검정해 보자. # 귀무 : 여아 신생아 몸무게의 평균은 2800(g)이다. # 대립 : 여아 신생아 몸무게의 평균은 2800(g)이 아니다. babyData = pd.read_csv('../testdata/babyboom.csv') print(babyData.head(3)) # print(babyData.describe()) fdata = babyData[babyData.gender == 1] # 여아는 1, 남아는 2로 가정 print(fdata, ' ', len(fdata)) # print(fdata.describe()) print(np.mean(fdata.weight)) # 3132.44 vs 2800 차이? # 정규분포 확인 # sns.distplot(fdata.iloc[:,2], kde=True) # plt.show() # stats.probplot(fdata.iloc[:,2], plot=plt) # Q-Q plot # plt.show() # print('정규성 :', stats.shapiro(fdata.iloc[:,2])) # pvalue=0.017984 < 0.05 이므로 정규성 만족 못함. 데이터에 문제가 있을 수 있으나 공부 중이니 그대로 진행. result4 = stats.ttest_1samp(fdata.weight, popmean = 2800) print('result4 : statistic(t-value) : {}, p-value : {}'.format(result4[0], result4[1])) # p-value : 0.03926 < 0.05 이므로 귀무가설 기각. 여아 신생아 몸무게의 평균은 2800(g)이 아니다. # ... 증가해서 뭐가 어쩌구 저쩌구... <console> time gender weight minutes 0 5 1 3837 5 1 104 1 3334 64 2 118 2 3554 78 time gender weight minutes 0 5 1 3837 5 1 104 1 3334 64 5 405 1 2208 245 6 407 1 1745 247 12 814 1 2576 494 13 909 1 3208 549 15 1049 1 3746 649 16 1053 1 3523 653 21 1406 1 3430 846 22 1407 1 3480 847 23 1433 1 3116 873 24 1446 1 3428 886 28 1742 1 2184 1062 30 1825 1 2383 1105 36 2010 1 3500 1210 41 2217 1 3866 1337 42 2327 1 3542 1407 43 2355 1 3278 1435 18 3132.4444444444443 result4 : statistic(t-value) : 2.233187669387536, p-value : 0.03926844173060218검정만으로 끝나는 것이 아니라, 검정의 결과를 바탕으로 무언가를 설명할 수 있어야 된다.

'Python 데이터 분석' 카테고리의 다른 글
one-sample t 검정 : 문제1 (0) 2022.11.08 기술통계의 대표값, 추론통계분석 모델의 비교(가설검정 방법의 종류, 추론통계 분석용 모델의 비교) (0) 2022.11.07 Python 데이터분석 기초 32 - t-test(집단 간 차이분석: 평균 또는 비율 차이를 분석), 실습 예제 1) 단일 표본 t 검정 (one-sample t- test) (0) 2022.11.07 카이제곱 검정 + 웹 연습 문제 (0) 2022.11.07 이원카이제곱 동질성 검정실습(2) (0) 2022.11.07