-
DB 데이터 불러와서 시각화 예제Python 데이터 분석 2022. 11. 2. 18:05

작성자 코드(A 5번 못 풀음... ㅠ)
import MySQLdb import numpy as np import pandas as pd import matplotlib.pyplot as plt from conda.common._logic import FALSE from matplotlib.pyplot import xlabel plt.rc('font', family='malgun gothic') plt.rcParams['axes.unicode_minus'] = False import pickle import csv try: with open('mydb.dat', mode='rb') as obj: config=pickle.load(obj) except Exception as e: print('connect err : ', e) try: conn=MySQLdb.connect(**config) cursor = conn.cursor() sql=""" select jikwon_no, jikwon_name, buser_name, jikwon_jik, jikwon_gen, jikwon_pay from jikwon inner join buser on buser_num=buser_no """ cursor.execute(sql) df1=pd.DataFrame(cursor.fetchall(), columns=['jikwon_no', 'jikwon_name', 'buser_name', 'jikwon_jik', 'jikwon_gen', 'jikwon_pay']) print(df1.head(3)) df = pd.read_sql(sql, conn) df.columns = ['번호','이름','부서','직급', '성별', '연봉'] with open("test.csv", mode='w', encoding='utf-8') as fo: writer = csv.writer(fo) for r in cursor: writer.writerow(r) print() jik_ypay = df.groupby(['직급'])['연봉'].sum() jik_max = df.groupby(['직급'])['연봉'].max() jik_min = df.groupby(['직급'])['연봉'].min() print(jik_ypay) print() print(jik_max) print() print(jik_min) print() ctab = pd.crosstab(df['부서'], df['직급'], margins = True) print(ctab) print() buser_mean = df.groupby(['부서'])['연봉'].mean() print(buser_mean) # 가로 막대 그래프 호출 plt.barh(['관리부', '영업부', '전산부', '총무부'],buser_mean) plt.show() print() gender_mean = df.groupby(['성별'])['연봉'].mean() print(gender_mean) plt.bar(['남', '여'],gender_mean) plt.show() print() ctab1 = pd.crosstab(df['성별'], df['부서'], margins = True) print(ctab1) except Exception as e: print('err :',e) finally: cursor.close() conn.close() <console> jikwon_no jikwon_name buser_name jikwon_jik jikwon_gen jikwon_pay 0 1 홍길동 총무부 이사 남 9900 1 2 한송이 영업부 부장 여 8800 2 3 이순신 영업부 과장 남 7900 직급 과장 43200 대리 35450 부장 25400 사원 45200 이사 9900 Name: 연봉, dtype: int64 직급 과장 7900 대리 5850 부장 8800 사원 4100 이사 9900 Name: 연봉, dtype: int64 직급 과장 5900 대리 4500 부장 8000 사원 2900 이사 9900 Name: 연봉, dtype: int64 직급 과장 대리 부장 사원 이사 All 부서 관리부 1 1 1 1 0 4 영업부 3 2 1 6 0 12 전산부 2 3 0 2 0 7 총무부 0 1 1 4 1 7 All 6 7 3 13 1 30 부서 관리부 6262.500000 영업부 4908.333333 전산부 5328.571429 총무부 5414.285714 Name: 연봉, dtype: float64 성별 남 5980.0 여 4630.0 Name: 연봉, dtype: float64 부서 관리부 영업부 전산부 총무부 All 성별 남 2 4 3 6 15 여 2 8 4 1 15 All 4 12 7 7 30
가로 막대 그래프 
세로 막대 그래프 선생님 코드 (A)
import MySQLdb import pandas as pd import pickle import matplotlib.pyplot as plt plt.rc('font', family='malgun gothic') import sys try : with open('mydb.dat', mode='rb') as obj: config = pickle.load(obj) except Exception as e: print('connect err : ', e) sys.exit() try: conn = MySQLdb.connect(**config) cursor = conn.cursor() sql = """ select jikwon_no, jikwon_name, buser_name, jikwon_pay, jikwon_jik from jikwon inner join buser on buser.buser_no = jikwon.buser_num """ cursor.execute(sql) df = pd.read_sql(sql, conn) df.columns = '사번','이름', '부서명', '연봉', '직급' df.index = range(1, 31) print(df.head(2)) print() print("부서별 연봉의 합 : ", df.groupby(['부서명'])['연봉'].sum()) print("부서별 연봉의 최대 : ", df.groupby(['부서명'])['연봉'].max()) print("부서별 연봉의 최소 : ", df.groupby(['부서명'])['연봉'].min()) print() print(pd.crosstab(df['부서명'], df['직급'], margins = True)) # 직원별 담당 고객자료를 출력 for i in range(1, len(df.index) - 1): sql2 = """ select gogek_no, gogek_name, gogek_tel from gogek inner join jikwon on gogek.gogek_damsano = jikwon.jikwon_no where jikwon_no = {} """.format(str(df.index[i])) #print(sql) cursor.execute(sql2) result = cursor.fetchone() if result == None: print(df['이름'][i + 1]," : 담당 고객 X") else: print(df['이름'][i + 1], '직원의 담당고객 정보') df2 = pd.read_sql(sql2, conn) df2.columns = ['고객번호', '고객명', '전화번호'] df2.set_index('고객번호', inplace=True) print(df2) # 부서명별 연봉의 평균으로 가로 막대 그래프 jik_ypay = df.groupby(['부서명'])['연봉'].mean() plt.barh(jik_ypay.index, jik_ypay.values) plt.show() except Exception as e: print("err : ", str(e)) finally: cursor.close() conn.close() <console> 사번 이름 부서명 연봉 직급 1 1 홍길동 총무부 9900 이사 2 2 한송이 영업부 8800 부장 부서별 연봉의 합 : 부서명 관리부 25050 영업부 58900 전산부 37300 총무부 37900 Name: 연봉, dtype: int64 부서별 연봉의 최대 : 부서명 관리부 8600 영업부 8800 전산부 7800 총무부 9900 Name: 연봉, dtype: int64 부서별 연봉의 최소 : 부서명 관리부 3400 영업부 2900 전산부 3900 총무부 3500 Name: 연봉, dtype: int64 직급 과장 대리 부장 사원 이사 All 부서명 관리부 1 1 1 1 0 4 영업부 3 2 1 6 0 12 전산부 2 3 0 2 0 7 총무부 0 1 1 4 1 7 All 6 7 3 13 1 30 한송이 직원의 담당고객 정보 고객명 전화번호 고객번호 5 차일호 02-294-2946 7 이분 02-546-2372 15 송운하 02-887-9344 이순신 직원의 담당고객 정보 고객명 전화번호 고객번호 2 김혜순 02-375-6946 3 최부자 02-692-8926 11 이영희 02-195-1764 이미라 직원의 담당고객 정보 고객명 전화번호 고객번호 9 장도리 02-496-1204 이순라 직원의 담당고객 정보 고객명 전화번호 고객번호 1 이나라 02-535-2580 8 신영래 031-948-0283 김이화 직원의 담당고객 정보 고객명 전화번호 고객번호 6 박상운 032-631-1204 김부만 : 담당 고객 X 김기만 : 담당 고객 X 채송화 직원의 담당고객 정보 고객명 전화번호 고객번호 12 이소리 02-296-1066 박치기 : 담당 고객 X 김부해 직원의 담당고객 정보 고객명 전화번호 고객번호 14 김현주 031-167-1884 박별나 직원의 담당고객 정보 고객명 전화번호 고객번호 10 강나루 032-341-2867 박명화 직원의 담당고객 정보 고객명 전화번호 고객번호 4 김해자 032-393-6277 박궁화 : 담당 고객 X 채미리 : 담당 고객 X 이유가 : 담당 고객 X 한국인 : 담당 고객 X 이순기 : 담당 고객 X 이유라 : 담당 고객 X 김유라 : 담당 고객 X 장비 : 담당 고객 X 김기욱 : 담당 고객 X 김기만 : 담당 고객 X 유비 : 담당 고객 X 박혁기 : 담당 고객 X 김나라 : 담당 고객 X 박하나 : 담당 고객 X 박명화 : 담당 고객 X 박가희 : 담당 고객 X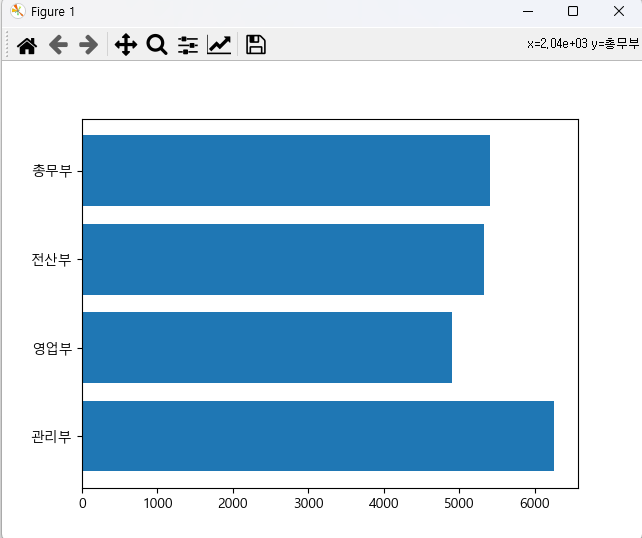
가로 막대 그래프 선생님 코드 (B)
# MariaDB에 저장된 jikwon 테이블을 이용하여 아래의 문제에 답하시오. # - pivot_table을 사용하여 성별 연봉의 평균을 출력 # - 성별(남, 여) 연봉의 평균으로 시각화 - 세로 막대 그래프 # - 부서명, 성별로 교차 테이블을 작성 (crosstab(부서, 성별)) import MySQLdb import pickle import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rc('font', family='malgun gothic') plt.rcParams['axes.unicode_minus'] = False import sys try : with open('mydb.dat', mode='rb') as obj: config = pickle.load(obj) except Exception as e: print('connect err : ', e) sys.exit() try: conn = MySQLdb.connect(**config) cursor = conn.cursor() sql = """ select buser_name,jikwon_gen,jikwon_pay from jikwon inner join buser on buser_num=buser_no """ print('pandas의 sql 처리 기능 사용해서 읽기') df = pd.read_sql(sql, conn) df.columns = ['부서','성별','연봉'] print(df.head(3)) print() print(df.pivot_table(values=['연봉'], index=['성별'], aggfunc=np.mean)) # 시각화 : 성별 연봉 평균 m = df[df['성별'] == '남'] m_pay_mean = m.loc[:,'연봉'].mean() f = df[df['성별'] == '여'] f_pay_mean = f.loc[:,'연봉'].mean() mean_pay = [m_pay_mean, f_pay_mean] plt.bar(range(len(mean_pay)), mean_pay, color=['black','yellow']) plt.xlabel('성별') plt.ylabel('연봉') plt.xticks(range(len(mean_pay)), labels=['남성','여성']) for i, v in enumerate(range(len(mean_pay))): plt.text(v, mean_pay[i], mean_pay[i], fontsize=12, color='blue', horizontalalignment='center', verticalalignment='bottom') plt.show() ctab = pd.crosstab(df['부서'], df['성별']) print(ctab) except Exception as e: print('처리 오류 : ', e) <console> pandas의 sql 처리 기능 사용해서 읽기 부서 성별 연봉 0 총무부 남 9900 1 영업부 여 8800 2 영업부 남 7900 연봉 성별 남 5980 여 4630 성별 남 여 부서 관리부 2 2 영업부 4 8 전산부 3 4 총무부 6 1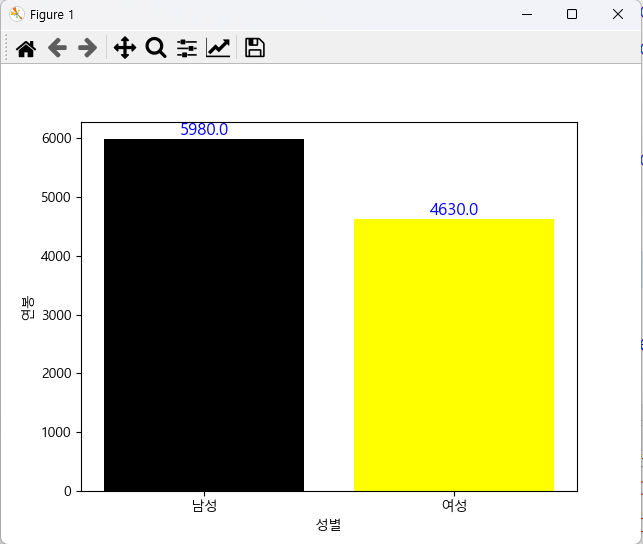
세로 막대 그래 'Python 데이터 분석' 카테고리의 다른 글
konlpy 설치 (0) 2022.11.03 Python 데이터분석 기초 23 - Django에서의 DataFrame, crosstab, 시각화 (0) 2022.11.03 Python 데이터분석 기초 22 - 원격 DB와 연동 후 DataFrame으로 처리, 시각 (0) 2022.11.02 Python 데이터분석 기초 21 - local DB와 pandas(sqlite에 DataFrame 넣기) (0) 2022.11.02 Python 데이터분석 기초 20 - 자전거 공유 시스템 시각화(web에서 데이터 가져옴), null 값이 있는 지에 대한 시각화, 칼럼 추가 (0) 2022.11.02