R
R 기초 26 - 로지스틱 회귀분석(Logistic Regression), underfitting 과 overfitting, train / test split, ROC curve
코딩탕탕
2022. 10. 27. 11:11
데이터를 두 개의 그룹으로 분류하는 문제에서 가장 기본적인 방법은 로지스틱 회귀분석이다.
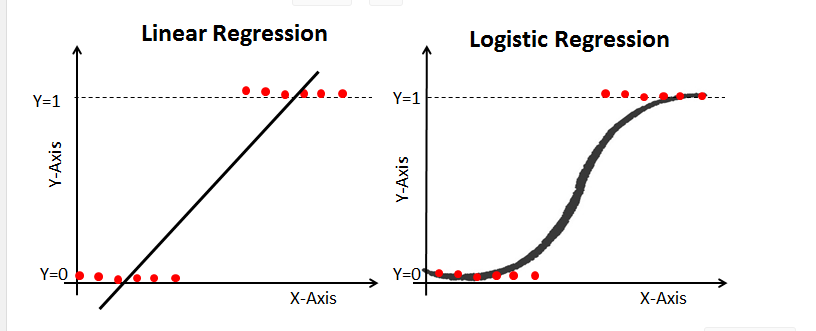
왼쪽이 지금까지 배운 선형회귀로(직선)이다. 로지스틱 회귀분석은 오른 쪽 그래프처럼 곡선으로 표시하기 위해 사용한다.
underfitting 과 overfitting
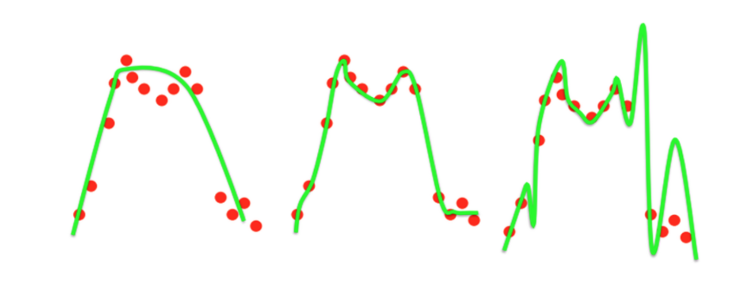
- 왼쪽은 지나친 단순화로 인해 에러가 많이 발생해 underfitting이라 합니다.
- 오른쪽은 너무 정확하게 표현한 나머지 training data에 대한 정확도는 좋지만 실제 test에서는 에러가 날 수 있는 상황이라 overfitting이라 합니다.
모델은 과대적합(Overfitting)과 과소적합(Underfitting)이 발생하지 않도록 설계하는 것이 중요합니다.
출처: https://22-22.tistory.com/35 [used to deeplearn:티스토리]
Logistic 방법(전통적인 방법)
# Logistic Regression : 독립변수 x(연속형)와 종속변속 y(범주형)를 사용해 결과를 범주로 분류분석함
# 분석 결과가 베르누이(동전 앞면, 뒷면 두 가지의 확률) 확률분포(이항분보)를 따름
# 분석 최종결과값에 시그모이드 함수를 사용하여 0 ~ 1 사이의 실수화 한 후 0.5를 기준으로 0, 1로 분류
getwd() # 경로를 불러온다.
setwd("C:/work/rsou/pro1") # 경로를 직접 입력
mydata <- read.csv("testdata/binary.csv")
head(mydata,3)
dim(mydata) # 400행 4열
unique(mydata$admit) # admit 값으로 무엇이 있는지 확인 0 1
summary(mydata)
table(mydata$admit, mydata$rank) # 표 작성 함수 1번째
xtabs(formula = ~admit + rank, data = mydata) # 표 작성 함수 2번째
# train / test split (7 : 3 or 8: 2)
set.seed(1) # 데이터를 랜덤하게 호출
idx <- sample(1:nrow(mydata), nrow(mydata) * 0.7)
length(idx) # 400행 중에 70%인 280행만 호출
idx
train <- mydata[idx, ] # 모델 학습용 dataset
test <- mydata[-idx, ] # 모델 검정용 dataset, idx를 뺀 나머지 120 행
dim(train) # 280 4
dim(test) # 120 4
head(train, 5)
head(test, 5)
# 모델 작성
lgmodel <- glm(formula = admit ~ ., data = train, family = binomial(link = 'logit')) # binomial함수는 이항일 때만 들어온다.
lgmodel
anova(lgmodel) # 집단의 평균의 차이를 구한다.
summary(lgmodel)
# 분류 예측으로 모델 검정
pred <- predict(lgmodel, newdata = test, type = 'response')
pred # 0.5 이상이면 합격!, 0.5 미만이면 불합격
head(ifelse(pred > 0.5, 1, 0), 10)
head(test$admit, 10)
# 모델의 분류 정확도 확인
result_pred <- ifelse(pred > 0.5, 1, 0)
t <- table(result_pred, test$admit)
t
# 정확확률 확인 방법 3가지
(77 + 11) / nrow(test) # accuracy(분류 정확도)
(t[1,1] + t[2,2]) / nrow(test)
sum(diag(t)) / nrow(test)
# 새로운 값으로 분류
newdata <- train[c(1:3), ]
newdata <- edit(newdata)
newdata
new_pred <- predict(lgmodel, newdata = newdata, type = 'response')
new_pred
ifelse(new_pred > 0.5, '합격', '불합격')train / test split으로 70%나 80%의 data를 학습시키고 30%나 20%를 검정용으로 사용한다. 앞서 말한 비율 정도로 주어도 된다. 100퍼센트를 주지 않는 이유는 train 데이터를 100% 학습시킨 후 test 데이터에 모델을 적용했을 때 성능이 생각보다 않 나오는 경우가 많기 때문이다.
물론 예측값과 실제값이 다를 확률도 있다.
ROC couve
ROC curve - 공돌이의 수학정리노트
angeloyeo.github.io